孪生网络训练
孪生神经网络(Siamese network),该网络常常用于检测输入进来的两张图片的相似性。
之前我们已经使用过yolov5对目标识别坐标了,
具体查看http://kjol.cc/yolov5-win10-gpu.html
标了100个样本坐训练。体力活啊
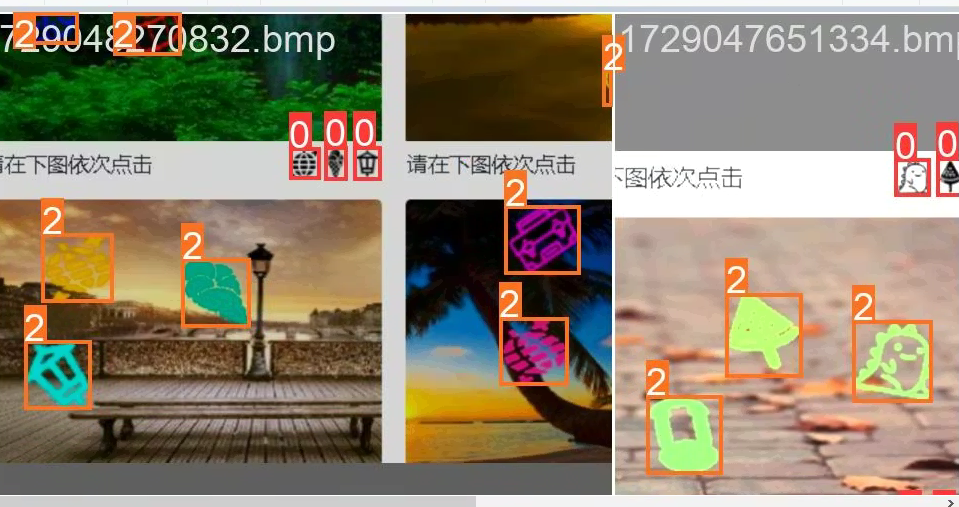
但是点选还差先点哪个后点哪个。
我的思路是,识别回来的0类,根据X坐标可以判断先后关系
网上思路我感觉过于复杂。还得分开训练大小图片。直接一古脑扔进去我感觉完事
然后把把识别出来的题目小图片,通过孪生神经网络跟2类对比相似度。接着排序好返回具体要点击的3个坐标。
由于博主菜鸟一个,基本功不够扎实,,加上时间有限,一时没弄出来,提前占坑。有空待续。。。
孪生网络样本分类
这2天空余时间人工分类,为后面的孪生网络做训练使用
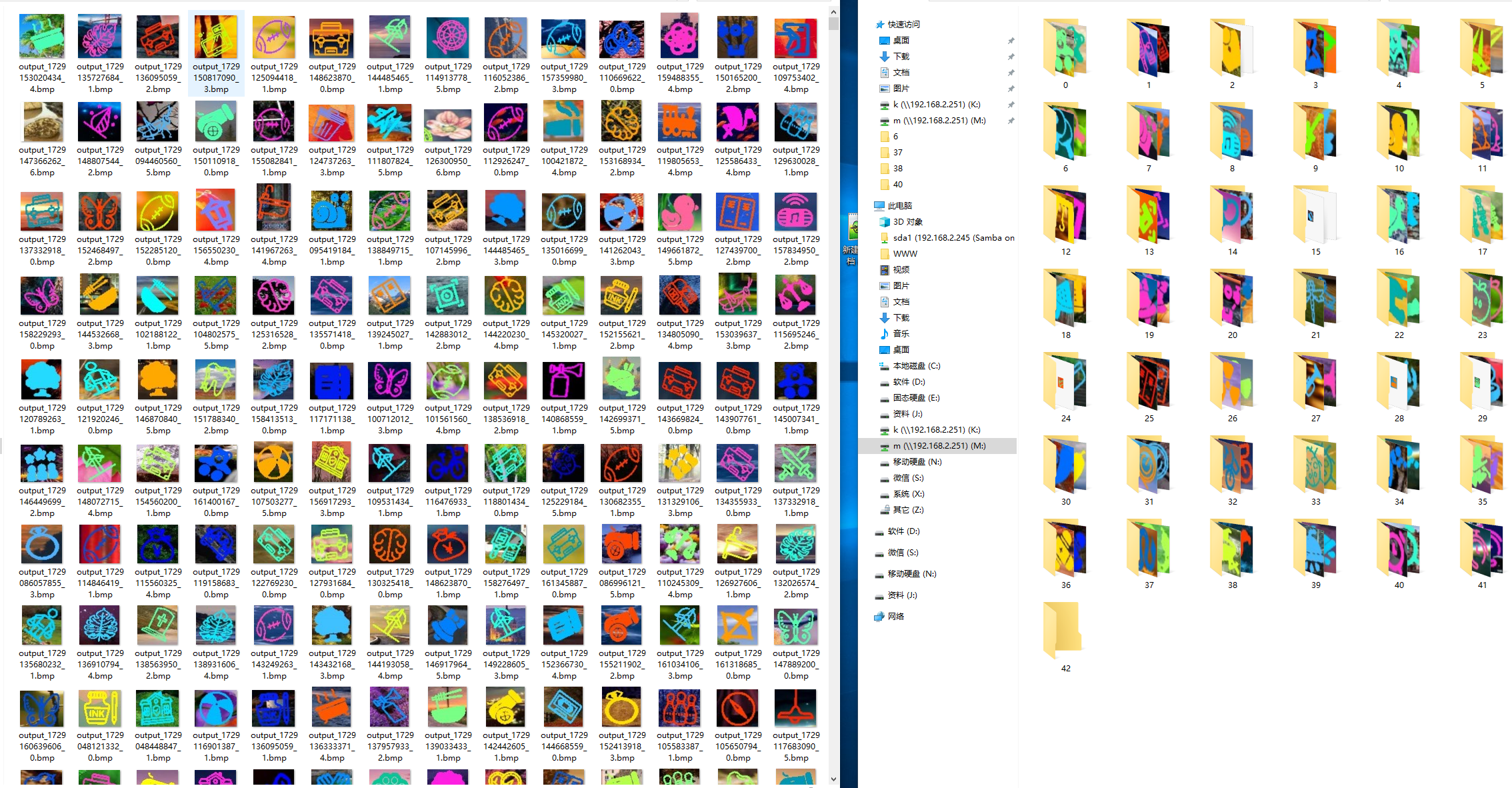
使用源码:https://github.com/bubbliiiing/siamese-pytorch/tree/bilibili
最后经过一顿操作猛乱改
终于YOLOV5识别目标坐标+孪生网络对比然后按循序输出了坐标。
目测成功率灰常高,比我用的打码平台都还高。毕竟自己亲自训练的
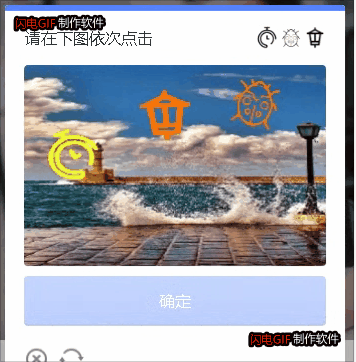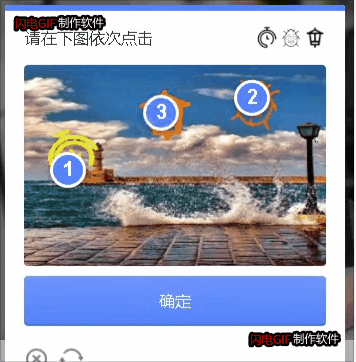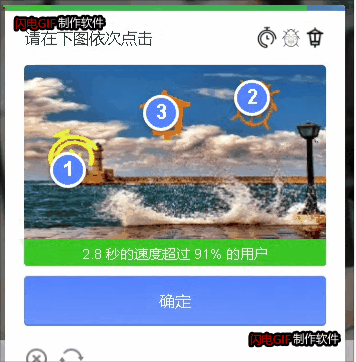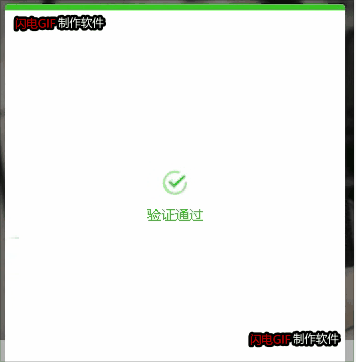
主要代码如下:
- import argparse
- import csv
- import os
- import platform
- import sys
- from pathlib import Path
- import numpy as np
- import torch
-
- FILE = Path(__file__).resolve()
- ROOT = FILE.parents[0] # YOLOv5 root directory
- if str(ROOT) not in sys.path:
- sys.path.append(str(ROOT)) # add ROOT to PATH
- ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
-
- from ultralytics.utils.plotting import Annotator, colors, save_one_box
-
- from models.common import DetectMultiBackend
- from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
- from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
- increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
- from utils.torch_utils import select_device, smart_inference_mode
-
- from models.experimental import attempt_load
- import base64
-
- from flask import Flask, request, Response,render_template
- import json
- import cv2
- import time
-
- from PIL import Image
- app = Flask(__name__)
-
- output_folder = 'runs/output' # 保存结果文件夹路径
-
- # 确保输出文件夹存在
- if not os.path.exists(output_folder):
- os.makedirs(output_folder)
-
-
- UPLOAD_FOLDER = r'./uploads'
- app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
- def base64_to_image(base64_code):
- # base64解码
- img_data = base64.b64decode(base64_code)
- # 转换为np数组
- img_array = np.fromstring(img_data, np.uint8)
- # 转换成opencv可用格式
- image_base64_dec = cv2.imdecode(img_array, cv2.COLOR_RGB2BGR)
- return image_base64_dec
-
-
- def redirect(source_path):
- stride = int(model.stride.max())
- imgsz = check_img_size(640, s=stride)
- detections = [] # 用于存储检测结果的列表
-
- im0s = cv2.imread(source_path)
- assert im0s is not None, "Failed to load image at path {}".format(source_path)
-
- # 转换颜色空间从BGR到RGB
- im0s = cv2.cvtColor(im0s, cv2.COLOR_BGR2RGB)
-
- # 调整图像尺寸以匹配模型期望的输入尺寸
- im0s = cv2.resize(im0s, (imgsz, imgsz))
- im = torch.from_numpy(im0s).to(device)
- im = im.half() if model.half else im.float()
- im /= 255
- im = im.permute(2, 0, 1)[None] # 重排维度并添加批次维度
-
- pred = model(im, augment=False, visualize=False)
- pred = non_max_suppression(pred, conf_thres, iou_thres, None, False, max_det=1000)
- below_50_detections = []
- above_50_detections = []
- for i, det in enumerate(pred):
- if len(det):
- det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0s.shape).round()
- for *xyxy, conf, cls in reversed(det):
- c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))
- if c1[1] < 50:
- below_50_detections.append((c1, c2))
- else:
- above_50_detections.append((c1, c2))
-
- # 根据左上角 x 坐标对检测结果进行排序
- below_50_detections.sort(key=lambda x: x[0][0])
- above_50_detections.sort(key=lambda x: x[0][1])
- seen=0
- max_similarity = 0
- most_similar_img = None
- top_similarities = [] # 用于存储所有相关图片的相似度和坐标
- for (c1, c2) in below_50_detections:
- seen += 1
- im0_pil = Image.fromarray(im0s)
- cropped_img = im0_pil.crop((c1[0], c1[1], c2[0], c2[1]))
- output_filename = f'output_{seen}.bmp'
- cropped_img.save(os.path.join(output_folder, output_filename))
- max_similarity = 0
- most_similar_above_c1 = None
- most_similar_above_c2 = None
-
- # 使用Siamese网络与大于50像素的图片进行相关性判断
- for above_c1, above_c2 in above_50_detections:
- above_im0_pil = Image.fromarray(im0s)
- above_cropped_img = above_im0_pil.crop((above_c1[0], above_c1[1], above_c2[0], above_c2[1]))
- # 确保above_cropped_img是PIL图像
- if not isinstance(above_cropped_img, Image.Image):
- above_cropped_img = Image.fromarray(above_cropped_img)
- similarity = siamese_model.detect_image(cropped_img, above_cropped_img)
- if similarity > max_similarity:
- max_similarity = similarity
- most_similar_above_c1 = above_c1
- most_similar_above_c2 = above_c2
- print(f"坐标: ({most_similar_above_c1[0]}, {most_similar_above_c1[1]}) - ({most_similar_above_c1[0]}, {most_similar_above_c1[1]})")
- # 保存图片
- above_im0_pil = Image.fromarray(im0s)
- above_cropped_img = above_im0_pil.crop((most_similar_above_c1[0], most_similar_above_c1[1], most_similar_above_c2[0], most_similar_above_c2[1]))
- output_filename = f'top_similar_{seen}.bmp'
- above_cropped_img.save(os.path.join(output_folder, output_filename))
- seen += 1
-
-
- # 输出大于50像素的坐标
- #for (c1, c2) in above_50_detections:
- # print(f"大于50像素的坐标: {c2[0]-c1[0]+c1[0]},{c2[1]-c2[1]+c2[1]}")
-
- return ''
-
- from siamese import Siamese
-
- def allowed_file(filename):
- return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
-
-
- import tempfile
- @app.route('/detect', methods=['POST'])
- def detect():
- file = request.files['file']
- if file:
- with tempfile.NamedTemporaryFile(delete=False) as tmp:
- tmp.write(file.read())
- tmp_path = tmp.name
- results = redirect(tmp_path)
- os.remove(tmp_path) # 删除临时文件
- return results
- return 'No file uploaded.', 400
- if __name__ == "__main__":
- #opt=parse_opt()
- #run(**vars(opt))
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- model = attempt_load(ROOT / 'sx.pt')
- model.to(device).eval()
- model.half()
- conf_thres = 0.65 # NMS置信度
- iou_thres = 0.45 # IOU阈值
- siamese_model = Siamese()
- #print(opt)
- app.run(host='0.0.0.0', port=5002, debug=True)
代码搓的难看。各位大神看看就好
还有最后图片需要归一化处理。不然坐标是不准的。
参考链接
https://www.sohu.com/a/751469426_120818776
https://zhuanlan.zhihu.com/p/678161348
感谢工具:https://kimi.moonshot.cn/