本文仅用于交流学习,请勿用于非法用途,后果自负!
参考文章:https://blog.csdn.net/LICAOPING/article/details/107623612
参考源码:https://github.com/JoeBili/bet365-websocket-crawler
前言
bet365是全球顶尖的涵盖足球篮球等各项赛事的赛事信息提供网站以及博彩网站。为啥要去爬这个网站呢?因为它赛事更新快,准,专业,赛事信息丰富。国内的很多赛事网站都是直接或者间接跟bet365的赛事信息有关系。
过程
有关第二个TOKEN得方法有变动。
还是逆向JS,艰辛过程省略。找合适得断点我都找了半天。反正没事多下断
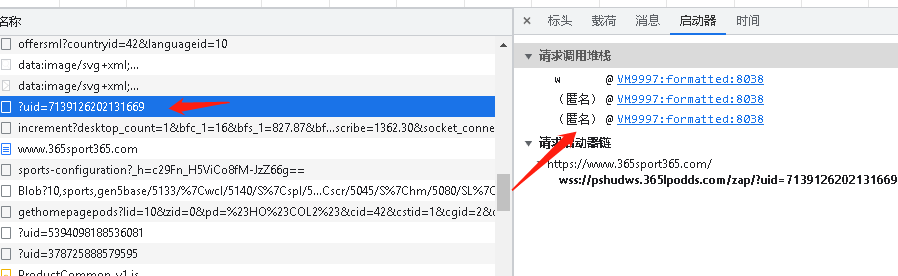
在堆栈里逆推找。最终定TOKEN出现
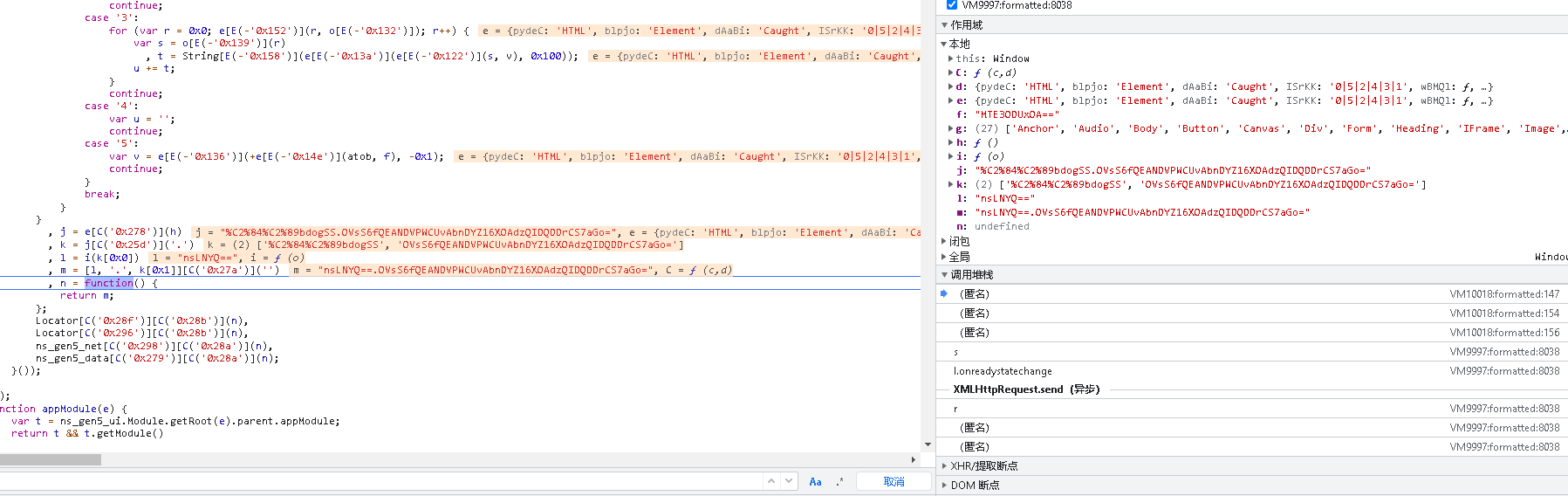
TOKEN出现之后。我们一步步往上看怎么得出来得。
TOKEN是由2部分组陈,是分割了J变量得到K[0]和k[1],k[0]经过i函数转换得到正确数值加上k[1]就是TOKEN.
其实我跟了整个流程。这整个闭包函数就是对k[0]进行解密操作。
需要给k[0]解密,需要2个变量。就是f,跟J
J跟f都是上层函数传过来得。这闭包没解密之前开始下断,断下,单步进入到如下
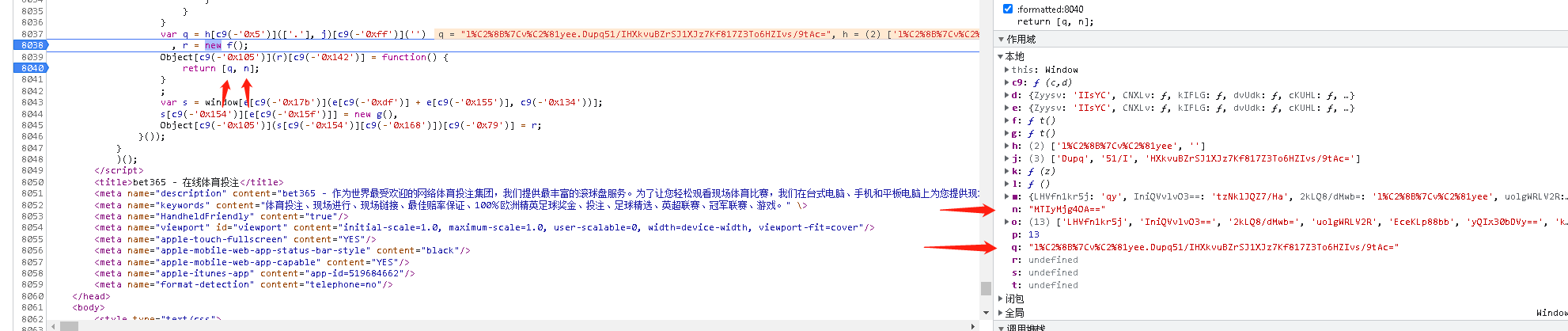
J跟f变量都在这里出现了。需要得就是q,n这2个数值。
我们继续往上推知道这些变量都是由a变量经过一系列得重组排列后得出来得

具体得运算跟开篇那博主说得差不多。不再啰嗦
注意得是。网站是动态生成得代码。所以需要自己根据特征扣片段代码进行解密
不能单独扣a变量下来直接进行运算。/
后面经过一顿修改GITHUB给出得py源码。
顺利成功获取数据流,good luck!!!
怎么可以调试的呢,想学都不知道从何入手,我F12调试,网站就转圈圈然后就说没有任何赛事。
不用调试模式就正常显示。
请教教。
时间有些久了,记不太清楚了。一般是对调试有监测,把检测点屏蔽跳过就好,可以找下相关资料看看
思路都是怎么找到检测点的? 简单又快的办法,是怎么样的?
熟能轻巧我知道这是有经验的人来说简单不过, 我都看了比较多的过逆向教程了,检测都点像那么大型的网站BET 365,有可能不会是像网上哪提到的对应方法 ,时间差 ,窗口大小 ,F12 热键。
过检测的都是怎么样的 思路来找到关键点?或有什么 特征码, 是扒下网站的所有JS然后逐一分析麽?分析经常HOOK【中间件】调试,是这样理解麽?
喜欢看逆向教程的,动手比较小估计自己也能理解点。做起来一头大。
我做简单网站成功过。 想大能你給点动力,我不想跑偏。
Hi
i have all data,but i can't connect with the wss//
i have problem with the ssl3 version.
can you help me please Regards
python有现成的模块可以直接连接的,具体看github的参考源码
365只打加球盘了解吗
不管啥盘,我已经列入黑名单