前言
用Python2写的一款小型的web目录扫描或Web文件扫描工具
根据提供的字典多线程对目标网站进行扫描
网上已经有很多开源和成熟的工具,为什么我们还要自己编?
因为我们要明白它的运行原理,或者我们可以对开源的工具进行修改
把优秀的代码拿来集成到自己工具里,不断扩展。从而达到我们的需求或目的
源代码
自己敲的代码很丑,请勿拍砖
- #-*-coding:utf-8-*-
- import urllib2
- import threading
- import Queue
- import urllib
-
- #定义目标,线程,初始化参数
- threads = 10
- target_rul = "http://www.xss.tv"
- wordlist_file = "/root/python/urls.lst"
- resumae = None
- user_agaent = "Mozilla/5.0 (X11; Linux i686; rv:45.0) Gecko/20100101 Firefox/45.0"
- Host = 'edu.xss.tv'
-
- #----------------------------------------------------------------------
- def build_wordlist(wordlist_file):
- #读入目录字典
- fd =open(wordlist_file, mode='rb')
- raw_words =fd.readlines()
- fd.close()
-
- found_resume = False
- #定义线程对象
- words = Queue.Queue()
- #print raw_words
- for word in raw_words:
- word =word.rstrip()
- if resumae is not None:
- if found_resume:
- words.put(word)
- else:
- if word ==resumae:
- found_resume =True
- print "Resume wordlist from:%s" % resumae
- else:
- words.put(word)
- return words
-
- #----------------------------------------------------------------------
- def dir_bruter(word_queue,extensions=None):
- while not word_queue.empty():
- #attempt =word_queue.get()
- attempt =word_queue.get_nowait()
- #attempt =get_nowait()
-
- attempt_list = []
-
- #检查是否为目录
- if "." not in attempt:
- attempt_list.append("%s/" % attempt)
- else:
- attempt_list.append("%s" % attempt)
- #print attempt_list
- #暴力扩展目录
- if extensions:
- for extension in extensions:
- attempt_list.append("/%s%s" % (attempt,extension))
- for brute in attempt_list:
- url = "%s%s" %(target_rul,urllib.quote(brute))
- try:
- headers ={}
- headers["User-Agant"] =user_agaent
- headers["Host"] =host
- r = urllib2.Request(url,headers=headers)
-
- response =urllib2.urlopen(r)
-
- #print response.read()
- if 'not found or template directory' not in response.read():
- print "[%d] => %s" %(response.code,url)
- except urllib2.URLError as e:
- #如需404,把屏蔽去了
- #if hasattr(e,'code') and e.code !=404:
- #print "!!! %d => %s" %(e.code,url)
- pass
-
- word_queue = build_wordlist(wordlist_file)
- #print word_queue
- extensions = [".php",".bak",".inc",".html","bak"]
-
- #开启线程
- for i in range(threads):
- t = threading.Thread(target=dir_bruter, args=(word_queue,None))
- t.start()
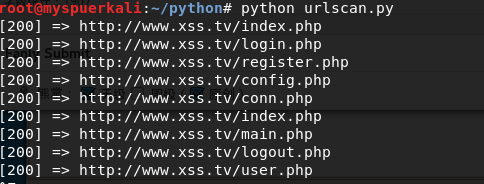
执行效果